Notebooks/Example2.ipynb
Example 2: Detecting the age-oxygen correlation¶
In Section 7 of Bixel & Apai (2021) (and in Bixel & Apai 2020), we propose that Earth-like planets might have similar atmospheric evolution to Earth’s, i.e. toward greater biogenic oxygen content over Gyr timescales. If so, this would imply a positive “age-oxygen correlation” between the fraction of Earth-like planets with atmospheric oxygen and their ages.
In this example, you will use Bioverse to determine whether a Nautilus-like transit spectroscopy survey could test this hypothesis.
Setup¶
We will begin by importing modules from Bioverse
[1]:
# Import numpy
import numpy as np
# Import the relevant modules
from bioverse.survey import TransitSurvey, prioritize_survey, read_scaling_dict
from bioverse.generator import Generator
from bioverse.hypothesis import Hypothesis
from bioverse import analysis, plots
# Import pyplot (for making plots later) and adjust some of its settings
from matplotlib import pyplot as plt
%matplotlib inline
plt.rcParams['font.size'] = 20.
In this example, we will use the simulator for a transit spectroscopy survey with an effecting diameter of 50 meters.
[2]:
generator = Generator('transit')
survey = TransitSurvey('default')
#start from the default Imaging survey and add an O2 observation
template_name='imaging_O2'
#import dictionary with reference times
scaling_dict=read_scaling_dict(template_name)
#set those reference times to be used in the exposure time calculation
survey.set_reference_observation(**scaling_dict)
#use a saved target prioritization scheme for the given observation
prioritize_survey(survey,template_name)
#add H2O measurement to survey measurements
survey.add_measurement('has_O2')
Injecting the statistical effect¶
We propose that the fraction of Earth-like planets with oxygen-rich atmospheres should increase over Gyr timescales. We can simulate this in Bioverse using a function with two parameters:
f_life: the fraction of exo-Earth candidates with lifet_half: the “half-life” timescale over which inhabited planets become oxygenated
Let’s define a function and append it to the generator.
[3]:
def oxygen_evolution(d, f_life=0.8, t_half=3.):
# First, assign no O2 to all planets
d['has_O2'] = np.zeros(len(d))
# Calculate the probability that each EEC has O2 based on its age
EEC = d['EEC']
P = f_life * (1 - 0.5**(d['age'][EEC]/t_half))
# Randomly assign O2 to some EECs
d['has_O2'][EEC] = np.random.uniform(0, 1, EEC.sum()) < P
return d
generator.insert_step(oxygen_evolution)
Next, we can simulate a dataset and investigate the relationship between the ages and oxygen content of EECs. For now, we assume f_life = 80% and t_half = 3 Gyr.
Note that the transit survey is more readily capable of detecting ozone than O2, as it has broader and deeper absorption bands and mostly resides above the cloud deck. We assume O3 is a reliable proxy for O2.
[4]:
# Create the planet sample
sample, detected, data = survey.quickrun(generator, f_life=0.8, t_half=3., t_total=10*365.25,d_max=100)
is_EEC= (data['EEC']==True)
# Extract measured ages and the presence of oxygen
x, y = data['age'][is_EEC], data['has_O2'][is_EEC]
# Now plot the oxygen-rich/oxygen-poor planets versus age
fig, ax = plt.subplots(figsize=(16, 2))
ax.scatter(x, y)
ax.set_yticks([0, 1])
ax.set_xlim([0,10])
ax.set_yticklabels(['no O$_2$','has O$_2$'],fontsize=24)
ax.set_xlabel('Age (Gyr)',fontsize=24)
plt.show()

As in Example 1, the expected trend appears to be present i.e. the presence of oxygen (via its proxy ozone) appears to correlate with age. But is this trend statistically significant?
Defining the hypothesis¶
To answer this, we will define a new Hypothesis. The functional form of this hypothesis will be the same as above i.e. a two-parameter decay rate function. As in the previous example, we must specify the names of the hypothesis parameters, independent variable (age), and dependent variable (has_O2) in the function signature. We again select log-uniform prior distributions for the two parameters:
0.01 < f_life < 1
0.3 < t_half < 30 Gyr
[5]:
def f(theta, X):
f_life, t_half = theta
return f_life * (1-0.5**(X/t_half))
params = ('f_life', 't_half')
features = ('age',)
labels = ('has_O2',)
bounds = np.array([[0.01, 1], [0.3, 30]])
h_age_oxygen = Hypothesis(f, bounds, params=params, features=features, labels=labels, log=(True, True))
We also need to define the null hypothesis, which states that the fraction of planets with O2 is (log-uniform) random between 0.001 to 1 and independent of age:
[6]:
def f_null(theta, X):
shape = (np.shape(X)[0], 1)
return np.full(shape, theta)
bounds_null = np.array([[0.001, 1.]])
h_age_oxygen.h_null = Hypothesis(f_null, bounds_null, params=('f_O2',), features=features, labels=labels, log=(True,))
We can calculate the Bayesian evidence supporting h_age_oxygen in favor of h_null from our simulated dataset.
[7]:
results = h_age_oxygen.fit(data)
print("The evidence in favor of the hypothesis is: dlnZ = {:.1f} (corresponds to p = {:.1E})".format(results['dlnZ'], np.exp(-results['dlnZ'])))
The evidence in favor of the hypothesis is: dlnZ = 29.3 (corresponds to p = 1.9E-13)
The default nested sampling test reveals some compelling evidence in favor of the hypothesis, but it may not be the most efficient test for this problem.
We can also use the Mann-Whitney U test to determine whether the typical age of planets with oxygen-rich atmospheres is higher than that of oxygen-poor planets. This test should be more sensitive, as it makes no specific assumptions about the functional form of the correlation (i.e. func defined above is not used).
[8]:
results = h_age_oxygen.fit(data, method='mannwhitney')
print('Correlation detected with p = {:.1E} significance'.format(results['p']))
Correlation detected with p = 9.0E-12 significance
Typically, the Mann-Whitney test detects the correlation with even greater significance (i.e. lower p-values)
Note for iPython/Jupyter users: We will need to reload the generator and h_age_oxygen objects here to replace the ones you have defined above. These will produce the same results, but the next code block uses the multiprocessing module which is incompatible with functions defined in iPython.
[9]:
generator = Generator('transit')
from bioverse.hypothesis import h_age_oxygen
Computing statistical power¶
Thus far, we have assumed the fraction of planets with life to be f_life = 80% and t_half = 3 Gyr. If fewer planets are inhabited, or if the evolutionary timescale is much longer than the maximum ages probed (~10 Gyr), then the correlation will be more difficult to detect. Let’s test the sensitivity of our results to both of these parameters simultaneously using the test_hypothesis_grid function.
Once again, we will use the more sensitive Mann-Whitney test to determine whether the correlation exists. This may take up to ten minutes - reduce N_grid for quicker results.
[ ]:
N_grid = 8
f_life = np.logspace(-1, 0, N_grid)
t_half = np.logspace(np.log10(0.5), np.log10(50), N_grid)
results = analysis.test_hypothesis_grid(h_age_oxygen, generator, survey, method='mannwhitney', f_life=f_life, t_half=t_half, N=20, processes=8, t_total=10*365.25)
11%|████▍ | 142/1280 [00:35<01:38, 11.50it/s]
Now, we will use the plot_power_grid() function of the plots module to plot the statistical power of the survey (i.e. the fraction of tests achieving p < 0.05 significance) versus both parameters.
[13]:
plots.plot_power_grid(results, method='p', axes=('f_life', 't_half'), labels=('Fraction of EECs w/ life', 'Oxygenation timescale (Gyr)'), log=(True, True), levels=None)

The “sweet spot” where high statistical power is achieved is where life is common (f_life > 50%) and the oxygenation timescale falls within ~2-10 Gyr.
We can also investigate the survey’s sensitivity as a function of total survey time. Let’s try values from 0.1 to 10 years, assuming f_life = 50% and t_half = 3 Gyr. This will take a few minutes.
[12]:
t_total = np.logspace(-1, 1, 10) * 365.25
results = analysis.test_hypothesis_grid(h_age_oxygen, generator, survey, method='mannwhitney', f_life=0.5, N=20, processes=8, t_total=t_total)
100%|█████████████████████████████████████████| 200/200 [00:22<00:00, 8.94it/s]
[15]:
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
ax[0].plot(t_total, results['p'].mean(axis=-1), lw=5)
ax[0].set_xlabel('Total time (d)', fontsize=20)
ax[0].set_ylabel('p', fontsize=20)
ax[0].axhline(0.05, lw=5, c='black', linestyle='dashed')
ax[0].set_xscale('log')
power = analysis.compute_statistical_power(results, method='p', threshold=0.05)
ax[1].plot(t_total, power, lw=5)
ax[1].set_xlabel('Total time (d)', fontsize=20)
ax[1].set_ylabel('Statistical power', fontsize=20)
ax[1].axhline(0.8, lw=5, c='black', linestyle='dashed')
ax[1].set_xscale('log')
plt.subplots_adjust(wspace=0.5)
plt.show()
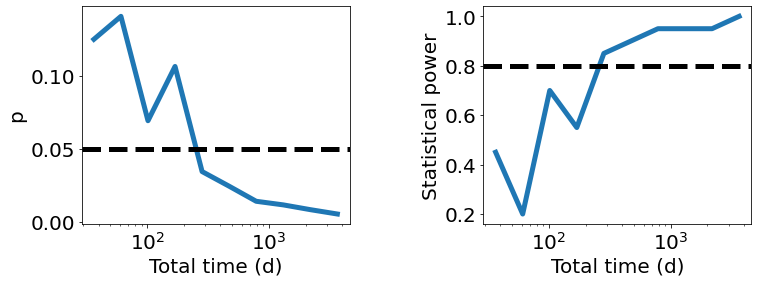
Approximately 1-2 years will be required to detect the correlation under these assumptions.